Research on possibility of RDBMS to have performance benchmarks like no-sql Databases
What is research ?
Research is complete reinvention of wheel to solve no of problems . A tweak or change in design to solve problems with less changes in Architecture is not research . For example features added to existing compiler of a language to support multiple cores is feature addition/versifying but writing a compiler for multiple core is research .
In this blog series we will see how a futuristic RDBMS will look like if some of the bottle necks can be handled .
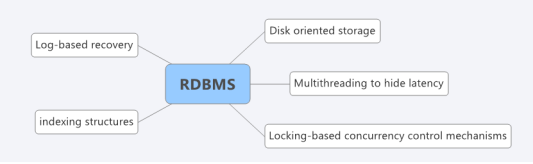
Today we will look into some bottlenecks of RDBMS which are related to transaction and processing.
If one assumes a grid of systems with main memory storage, builtin high availability, no user stalls, and useful transaction work under 1 millisecond, then the following conclusions become
evident:
1) A persistent redo log is almost guaranteed to be a significant performance bottleneck. Even with group commit, forced writes of commit records can add milliseconds to the runtime
of each transaction.
2) With redo gone, getting transactions into and out of the system is likely to be the next significant bottleneck. The overhead of JDBC/ODBC style interfaces will be onerous,
and something more efficient should be used. In particular, running application logic – in the form of stored procedures – “in process” inside the database system, rather than the inter-process overheads implied by the traditional database client / server model.
3) An undo log should be eliminated wherever practical, since it will also be a significant bottleneck.
4) Every effort should be made to eliminate the cost of traditional dynamic locking for concurrency control, which will also be a bottleneck.
5) The latching associated with multi-threaded data structures is likely to be onerous. Given the short runtime of transactions, moving to a single threaded execution model will eliminate
this overhead at little loss in performance.
6) One should avoid a two-phase commit protocol for distributed transactions, wherever possible, as network latencies imposed by round trip communications in 2PC often take on the order of milliseconds.
Our ability to remove concurrency control, commit processing and undo logging depends on several characteristics of OLTP schemas and transaction workloads, a topic to which we will cover in next post.

Research on possibility of RDBMS to have performance benchmarks like no-sql Databases | ratneshparihar 11:40 am on July 28, 2014 Permalink |
[…] Research on possibility of RDBMS to have performance benchmarks like no-sql Databases […]
LikeLike
Research on possibility of RDBMS to have performance benchmarks like no-sql Databases (part 2) | ratneshparihar 5:13 am on July 29, 2014 Permalink |
[…] Research on possibility of RDBMS to have performance benchmarks like no-sql Databases […]
LikeLike
ratneshparihar 8:24 am on August 6, 2014 Permalink |
got a comment
http://www.sqlservercentral.com/Forums/Topic1599687-373-1.aspx#bm1599997
————————————————————————————————————————-
The 6 points raised in the first post of teh series are all a bit boring/mundane and don’t, for me, address the title (which in any case is ambiguous) at all.
Taking the title first, it’s not clear whether you are looking at the possiblity of benchmark results for RDBMS similar to those obtained for no-sql databases or for benchmarks of similar workloads on no-sql databases and on RDBMS.
I’ll comment on your 6 numbered points in order:
1) Abandoning a persistent redo log means abandoning the ability to recover from system breaks unless it means insisting that when and where where a log-based system would secure redo data in the log the system secures it in the main persistent data store. The performance penalty of securing data in main persistent data store at an early enough point to provide an acceptable recovery capability is far greater than the penalty of securing the data in a redo log unless the recovery requirement is extremely weak.
2) The relational model makes no statement about what business logic can be included in the database, other than that those business rules which can be used to determine normality of schemas must be in the database. There are of course people who claim that no business rule should ever be in the database, which of course is nonsense because that would mean that no normalisation could ever be carried out. There are others who claim that no business logic other than that implemented as normalisation (in the form of keys and constraints) should ever be in the database, but that is not an RDBMS vs No-Sql distinction, the same people who make that claim about RDBMS make it also about no-sql databases; it will often be nonsense for RDBMS, since a single SQL statement carrying out a MERGE and a PIVOT a couple of joins and a projection or two actually embodies a large amount of business logic and the proponents of “no business logic in the database” are careful to stress that this business logic doesn’t count as business logic lest they been seen as totally inept. Principles of modular design tend to separate logic in such a way as to maximise the narrowness of inter-component interfaces, and also to ensure that components which run in different contexts are sufficiently large that the context switching overhead is not unacceptably great, and modular design is equally important in no-sql systems and in RDBMS. So I find it hard to believe that point 2 says anything at all about difference between RDBMS and No-Sql.
3) An undo log can be eliminated only when it is guaranteed that the system never fails, unless it is acceptable for part of a transaction to be done and the rest not; moving money from one account to another is a nice example of where this is usually not acceptable. The RDBMS view is that it is so rare for this to be acceptable that the simplicity of always having the undo log rather than sometimes having it and sometimes not is better than the complication of not having it in the rare cases where it is not needed (for example where no transaction ever updates more than one value in the database). A different argument can be made for writing the undo log as rarely as possible – that nothing should be written to the undo log until it is neccesary to write data which may need redoing to permanent store; but that’s a considerably weaker position that your point 3, and it’s still possible that on the whole it is better to keep things simple and always log undo information.
4) Sql Server currently provides a range of isolation levels, not all of which use traditional locking. Depending on the workload, tradiditional locking may deliver better or worse performance than maintaining mulitple consistent views. The idea that traditinal locking always costs more than the alternatives is pure nonsense.
5) Single threaded execution will only deliver decent performance when all IO latencies are very low indeed. Asynchronous IO at some level is necessary for most workloads to run efficiantly on most hardware, and Asynchronous IO won’t deliver the required concurrency unless it is used to assist multi-threading. This is true whether there is a formal RDBMS or N-SqL database or just a bunch of ad-hoc files with no formal database concept.
6) Two-phase commit should be avoided where possible is an overstatement; it should not be avoided when it is more efficient and/or more acceptable than the alternatives. It is always possible to avoid it, although it may or may not be efficient or accptable to do so (for example the system could be made to hold all data at one central location, so that there would no requirement at all for two-phase commit).
Tom
————————————————————————————————————————-
LikeLike
ratneshparihar 8:55 am on August 6, 2014 Permalink |
Thank you Tom for providing feedback .
Yes , title is little out of context and i put that way intentionally (backfired though) because i am hearing a lot that for a RDBMS will be difficult to have the Webscale like no-sql Dbs are providing , But it is difficult to understand why they can’t . Now there are vendors in OLTP market to claim have that and in order to evaluate we have to understand how a futuristic RDBMS can handle if Moder hardware (mostly memory and cpu ) is cheap .
Simply , i am not bench marking anything here just putting some thoughts what criterion will help us to decide next OLTP for our future application . sql-server , oracle are written on 30 year old architecture and complete redesign is required if they are competing with modern OLTPs.
I am completely agree on your feedback for all 6 points as far as current state of RDBMS are concern , but you can visualize a OLTP completely on MainMemory and other non oltp issues on Datawarehouse (columnar ) then all transaction will be very small and all processing will indeed occur in mainmemory and no need of file handles either for accessing datapages for accessing log files and the whole database will be a cluster of multiple PCs .
If you consider above scenario and look again into 6 points i mentioned , then they might make sense . Since both distributed processing and memory is getting cheap and feasible the whole ecosystem around the RDBMS is likely to be changed and vendors has started to build systems without long lasting transaction logs , two phase commits and locking ofcourse .
LikeLike